Introduction
Afrim is an input method originally designed for the sequential code. Currently, the afrim supports any sequencial coding system.
- Support for any sequencial coding system.
- Suggestion and auto-completion.
- Written in Rust for speed, safety, and simplicity.
- Support for frontend interface.
This guide is a manual of usage of the afrim input method.
Contributing
Afrim is free and open source. You can find the code on Github and issues and feature requests can be posted on the Github issue tracker. Afrim relies on the community to fix bugs and add features: if you'd like to contribute, please read the CONTRIBUTING guide and consider opening a pull request.
License
The afrim source code and documentation are released under the MIT.
Installation
There are multiple ways to install Afrim input method. Choose any one of the methods below that best suit your needs.
Pre-compiled binaries
Executable binaries are available for download on the Github Releases page. Download the binary for your platform (Windows, macOS, or Linux) and extract the archive. The archive contains an afrim executable.
To make it easier to run, put the path to the binary into your PATH.
Build from source using Rust
To build afrim executable from source, you will first need to install Rust and Cargo. Follow the instructions on the Rust installation page. Afrim currently requires at least Rust version 1.7 for performance.
Once you have installed Rust, the following command can be used to build and install afrim:
cargo install afrim
This will automatically download afrim from crates.io, build it, and install it in Cargo's global binary directory (~/.cargo/bin/ by default).
To uninstall, run the command cargo uninstall afrim.
Installing the latest master version
The version published to crates.io will ever so slightly be behind the version hosted on GitHub. If you need the lastest version, you can build the git version of afrim yourself. Cargo makes this super easy!
cargo install --git https://github.com/pythonbrad/afrim.git afrim
Again, make sure to add the Cargo bin directory to your PATH.
If you are interested in making modifications to afrim itself, checkout the Contributing Guide for more information.
Usage
Once you have the afrim installed, you can use it.
But before you should download or write your own configuration file.
You can download a official dataset via the Afrim Dataset Repository.
Sample configuration file
# config.toml
[core]
buffer_size = 64
[data]
a1 = "à"
[translation]
hi = "hello"
Check out the Configuration Guide for more information about how to write a configuration file.
Demo
Considering the sample configuration file above, you can run the afrim with this command afrim config.toml.
Configuration
This section details how to write a configuration file.
Here is an example of what a configuration file might look like:
# amharic-ime/config/conf.toml
[core]
buffer_size = 64
page_size = 16
auto_commit = false
[translators]
geez_numerals = "../data/geez/scripts/numerals.rhai"
[translation]
amharic_words = { path = "../data/amharic/dictionary.toml" }
amharic_names = { path = "../data/amharic/names.toml" }
[data]
geez = { path = "../data/geez/code.toml" }
Supported configuration options
It's important to note that any relative path specified in the configuration will always be taken from the path where the configuration file is located.
- Core configuration to modify the internal behavior of afrim.
- Data configuration to setup a sequential coding system.
- Translator configuration for auto-suggestions.
Core configuration
Here is an example of what the core configuration might look like.
# afrim/conf/conf.toml
[core]
buffer_size = 64
page_size = 16
auto_commit = false
auto_capitalize = false
- buffer_size: The memory allowed to the input text.
- page_size: The maximun number of suggestions that should be display.
- auto_commit: Tell to afrim if the first suggestion got, should be submitted or not.
- auto_capitalize: Tell to afrim to generate the capitalize version of the sequential coding system of the current configuration file.
NB: Only the core configuration at the root configuration file is considered (except for the auto_capitalize field who is file oriented).
Data Configuration
Here is an example of what the data configuration might look like.
# clafrica/data/clafrica_double.toml
[info]
name = "Clafrica double"
description = "Clafrica code for speed typing of double characters"
authors = ["Resulam <contact@resulam.com>"]
website = "https://resulam.com"
version = "2023-07-06"
[data]
"a11" = { value = "àà", alias = ["1aa", "aa1"] }
"a22" = { value = "áá", alias = ["2aa", "aa2"] }
"a33" = { value = "āā", alias = ["3aa", "aa3"] }
"a55" = { value = "ââ", alias = ["5aa", "aa5"] }
"a77" = { value = "ǎǎ", alias = ["7aa", "aa7"] }
"aff" = "ɑɑ"
"aff1" = { value = "ɑ̀ɑ̀", alias = ["1aff", "af11"] }
"aff2" = { value = "ɑ́ɑ́", alias = ["2aff", "af22"] }
"aff3" = { value = "ɑ̄ɑ̄", alias = ["3aff", "af33"] }
"aff5" = { value = "ɑ̂ɑ̂", alias = ["5aff", "af55"] }
"aff7" = { value = "ɑ̌ɑ̌", alias = ["7aff", "af77"] }
...
We can see that there is two ways to represent data.
- Simple: Key - Value representation.
- Detailed: Suitable for code with alias.
Translator Configuration
Here is an example of what the translator configuration might look like.
# amharic/data/names.toml
[info]
source = "https://github.com/Simonbelete/kwat/blob/main/names/names.csv"
description = "Ethiopic name"
version = "2023-09-15"
[translation]
"Eman" = "ኢማን"
"Addis" = { values = ["ሰኢድ", "አዲስ"], alias = ["EIads", "eiads", "eIads", "Eiads", "Seid"] }
"Shimei" = { value = "ሰሜኢ", alias = ["eIasm", "EIasm", "eiasm", "eiasM", "eIasM", "EiasM", "Eiasm", "EIasM"] }
...
We have 4 ways to represent the translator configuration.
- Simple: Key - Value representation.
- Detailed: Suitable when we want to use alias.
- More Detailed: Suitable when we can have many values.
- Scripting: Suitable for complex suggestions (date, number, etc.). For more details about it confer Translator for Developers.
For developers
While `afrim is mainly used as a binary application, you can also import the core library directly and use that to build your own input method. In this chapter, we will talk about how to customize the internal working of afrim. Afrim supports Rhai scripting language for some customization.
The For Developers chapters are here to show you the more advanced usage of afrim.
The two main ways a developer can hook into the afrim working is via,
Afrim Brief Architecture
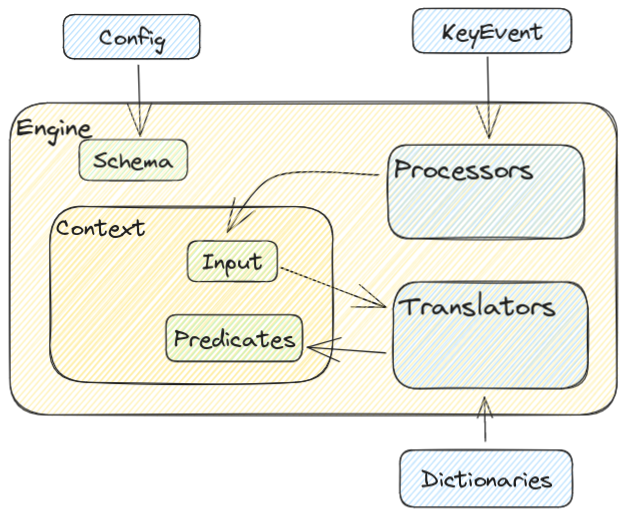
Afrim Working
The working of afrim goes through several steps.
- Listening keyboard events
- Identify the event
- Identify the operation to perform
- For each translator:
- Perform the translation
- Return the predicates
- Display useful information through the frontend interface
Processor
The processor is simply the part of afrim who manage the I/O operations via the keyboard, allowing you insert and remove character in the sequence. Possible use cases are:
- Insert a character in the sequence.
- Clear the sequence.
- Commit the corresponding output of a sequence.
- Rollback a previous commit.
For the moment, no customization can be done at this level.
Translator
A "translator" is simply a program which afrim will invoke during the translation process, allowing you to use programmable predictions. Possible use cases are:
- Auto-correction
- Auto-suggestion
The fact that afrim utilizes The Rhai Scripting Language makes it easy to implement a simple translator.
The following code block shows how to write a translator who suggest a date in another format.
// scripts/datetime/date.rhai
const MONTHS = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"];
fn parse_cmd(input) {
let data = input.split('_');
if data.len() == 3 {
return data[1];
}
return "";
}
fn parse_date(input) {
let data = input.split('/');
if data.len() == 3 {
let day = parse_int(data[0]);
let month = parse_int(data[1]);
let year = parse_int(data[2]);
if day in 1..31 && month in 1..12 && year in 1..2100 {
return [day, month, year];
}
}
return [];
}
// Main function
fn translate(input) {
let data = parse_cmd(input);
let date = parse_date(data);
if !date.is_empty() {
return [input, "", [`${date[0]} ${global::MONTHS[date[1]]} ${date[2]}`, `${global::MONTHS[date[1]]} ${date[0]} ${date[2]}`], true];
}
return [input, "", "", false];
}
The most important part of this code, is the translate function. All translator should have this function. His signature is as follo:
- input: The current user input (String).
- output: A list of value (Array).
- The user input (String).
- The remaining code to complete the user input (String).
- The translator output (String|Array).
- If the translation is ready to use (Boolean).
The syntax of the translator configuration is as below.
# scripts/datetime/datetime.toml
[translators]
date = "./date.rhai"
time = "./time.rhai"
Frontend
Because the frontend is an external feature of afrim, his customization don't depend on him. Hence, we will not cover it.
Useful Ressources
Here is a list of useful link who can help for the configuration of the afrim.
- The Rust Programing Language
- The Rhai Scripting Language
- Tom's Obvious Minimal Language
- Afrim Dataset
Contributors
Afrim was developed by Brady Fomegne (pythonbrad).